raw 클라우드 포인터를 딥러닝의 input으로 사용하려는 시도에 대해 공부해보려고 한다. PointNet라는 논문에 대해 정리해보도록 하겠다.
PointNet은 Classification, Segmentation에 모두 적용될 수 있지만 이 글에서는 Classification에 대해서만 다루기로 하겠다.
Classification Task
PointNet을 설명하기 전에 Classification 문제의 기본 구조를 설명하도록 하겠다.
GT
이 논문에서는 Dataset으로 ModelNet40을 사용했다. ModelNet40은 인위적으로 만들어진 오브젝트의 클라우드 포인트를 담고 있다. 12,311개의 이미지가 있으며 40개의 카테고리가 있다. 9,843개는 트레이닝을 위해 2,468개는 테스트를 위해 쓰인다. 포인트 클라우드 데이터는 메쉬 표면에서 샘플링 했으며 전처리 과정을 거쳤다.

따라서 Classiffication에 있어서 Gound Truth는 위 데이터셋의 부류값이 되겠다.
Input
모델의 인풋으로 들어가는 것은 오브젝트를 나타내는 클라우드 포인터가 되겠다. 포인트 클라우드는 보통 {x,y,z,c}의 값을 갖는다. 이 때 c는 color 정보를 담고 있다. 허나 이 논문에서는 c값을 제외한 {x,y,z} 값을 사용한다.
이 논문에서 가장 중요한 부분이 인풋이다. input 값이 point cloud여서 발생하는 문제가 많다. 이를 해결하려고 시도한 것이 PointNet이다. 이에 대해선 PointNet섹션에서 다루도록 하겠다.
Output
모델의 아웃풋으로 나오는 값은 모델의 부류에 따른 확률값이다. ModelNet Dataset을 예로 들면 40개의 카테고리가 있으니 40개의 output이 나오는 셈이다.
Metric
Classification에는 보통 accuracy가 사용된다.
\[\frac{TP+TN}{TP+TN+FP+FN}\]Loss Function
Classification에서는 보통 CrossEntropy가 사용된다.
PointNet
Cloud Point의 특징
- cloud point는 순서와 무관하다.(invariant to permutation)
- 음성 신호는 x축을 시간 축으로 y축을 음량으로 한다. 그리고 읽을 때는 시간축을 따라 읽는다. 하지만 cloud point를 표현할 때는 x축 y축 z축이 있고 해당 좌표에 점을 찍는다. 읽을 때는 어떻게 읽는가? 시간 순서대로 읽는가?(애초에 시간이 있나?) cloud point는 어떤 순서로 읽어야할지 정해지지 않았다.
- cloud point는 주변의 point와 연관이 있다.(local structure)
- point는 자기 자신만으로는 의미를 만들어내지 못한다. 주변의 포인트들과의 거리를 통해 의미를 만들어낸다. 따라서 local한 정보가 중요하다.
- cloud point는 transform에도 의미를 잃지 않는다.(invariant to transform)
- 전체 point cloud를 돌리거나 이동시키더라도 원래의 의미를 잃지 않는다. 의자는 여전히 의자고 차는 여전히 차다.
PointNet의 특징
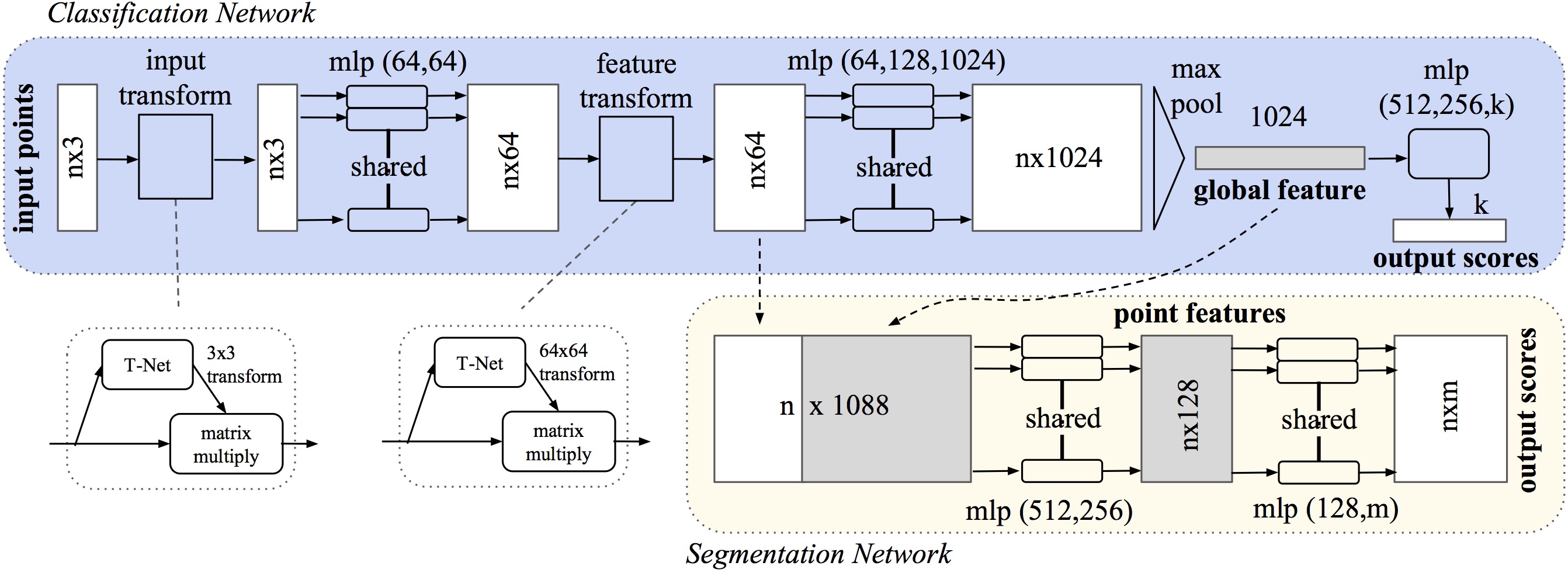
Symmetry Function
input값의 순서에 상관없이 항상 일정한 값을 내는 function을 말한다. 예를 들면 n개의 벡터가 있다면 이 n개의 벡터를 어떻게 섞어서 더해도 값은 같다. 이 때 더하기는 Symmetry Function이 된다. Symmetry Funtion을 사용하면 나타내는 오브젝트는 같지만 정렬은 다른 포인트 클라우드에 대해 같은 값을 만들 수 있다.
PointNet에서는 Symmetry Function으로 maxpool을 쓴다.
Local and Global Information Aggregation
이것은 Classification 문제가 아니라 Segmentation 문제에 사용된다. 보통 Cloud Point Classification Dataset은 하나의 물체만 담겨있기에 Gobal이 곧 Local이다. 하지만 Segmentation 문제는 Global과 Local을 분류해줄 필요가 있다.
Local 정보를 반영하기 위해서 PointNet에서는 Global feature와 Local Feature를 Concat해준다.
Joint Alignment Network
cloud point는 Transform에 불변하다고 했다. 이 논문의 저자는 input 뿐만 아니라 extracted feature 또한 Transform에 불변해야한다고 생각했다. 그래서 Affine Transformation을 예측해서 input과 feature에 적용한다.
이를 위해 T-Net이 사용된다. 사실상 Data Augmentation이라고 봐도 될 것 같다.
또 feature에 적용되는 Transform에는 특별한 제약사항이 걸린다.
\[L_{reg} = ||I - AA^T ||^2_F\] \[AA^T{를} I{에 가깝게 만들겠다는 뜻이다.}\]즉 A가 직교행렬이 되기를 원한다. A가 직교행렬이 되면 A를 적용한 변환은 벡터의 길이를 보존하고 벡터 사이의 각도도 보존한다. 이러한 제약을 거는 이유는 feature space의 크기가 커 변환 매트릭스 A의 최적화가 어렵기 때문이다.